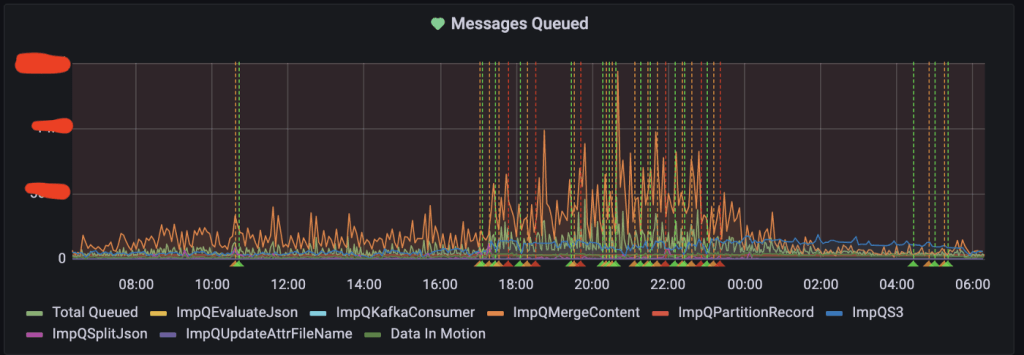
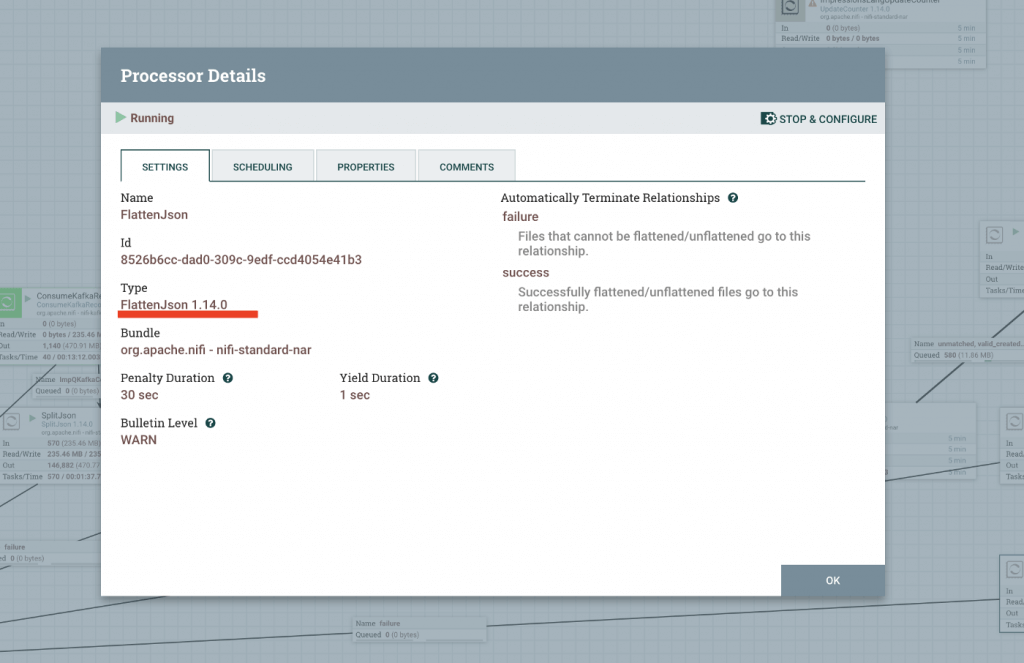
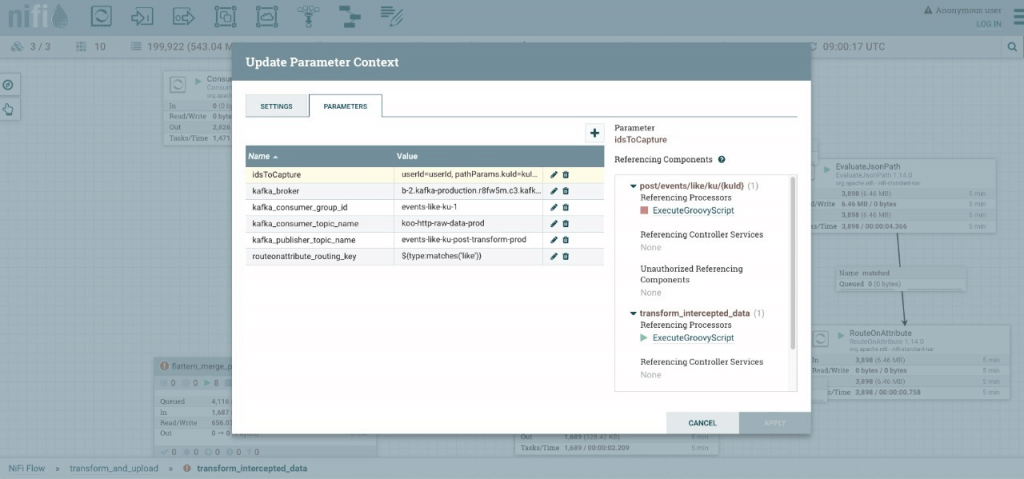
कूचा डेटा प्लॅटफॉर्म — भाग १: Apache Kafka and NiFi

लोकप्रिय पोस्ट

समुदाय मार्गदर्शक तत्त्वे
2022-05-06 10:57:29
वार्षीक परतावा
2022-05-06 13:35:40
कू सल्लागार मंडळ
2022-05-06 11:51:31
भाषा
2022-05-10 10:17:27